
How to Build a RAG Chatbot Using Embed: A Step-by-Step Guide
Best GPTs Developer
431 words

How to Build a RAG Chatbot Using Embed: A Step-by-Step Guide
In the ever-evolving landscape of artificial intelligence and chatbot technology, leveraging the right tools and frameworks is crucial for developers aiming to create sophisticated and responsive chatbots. One such innovative approach involves using Retrieval-Augmented Generation (RAG) alongside Embed, a versatile online service. This article will guide you through the process of building a RAG chatbot that utilizes Embed to train on various data sources, including PDFs, URLs, and plain text documents.
Understanding Embed: A Quick Overview
Embed is an online service that facilitates the training of diverse data sources such as PDFs, URLs, and plain text files. This platform stands out by allowing developers to easily integrate a wide range of knowledge into their applications or chatbots. For a detailed introduction to Embed and its capabilities, consider reading the quick-start guide.
By building a knowledge base with Embed, developers can access this information through an API, simplifying the creation of RAG chatbots. This combination opens up new possibilities for chatbot applications by enhancing their ability to understand and respond to user queries more accurately.
Step-by-Step Construction of a RAG Chatbot
For this tutorial, we’ll focus on creating a chatbot designed to answer questions related to a personal resume. The process involves training the chatbot with a resume PDF and then querying this knowledge base using an API.
Training the Resume PDF
First, upload and train your resume PDF on Embed as illustrated below:
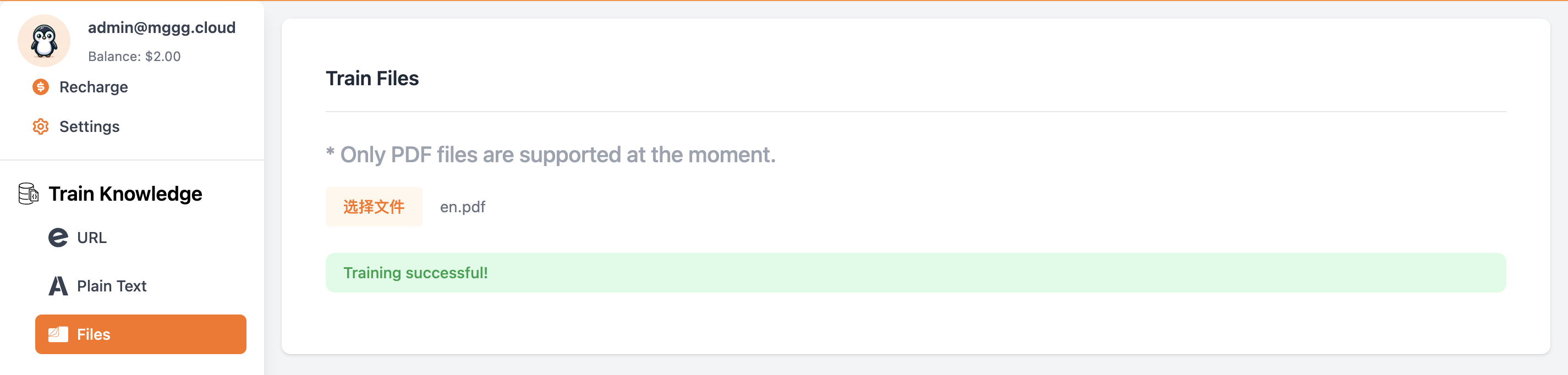
After successfully training the PDF, you can review the training results to ensure the data has been correctly processed.
Querying Knowledge Using the API
To interact with your trained knowledge base, you’ll need to obtain an API key from the Settings menu:
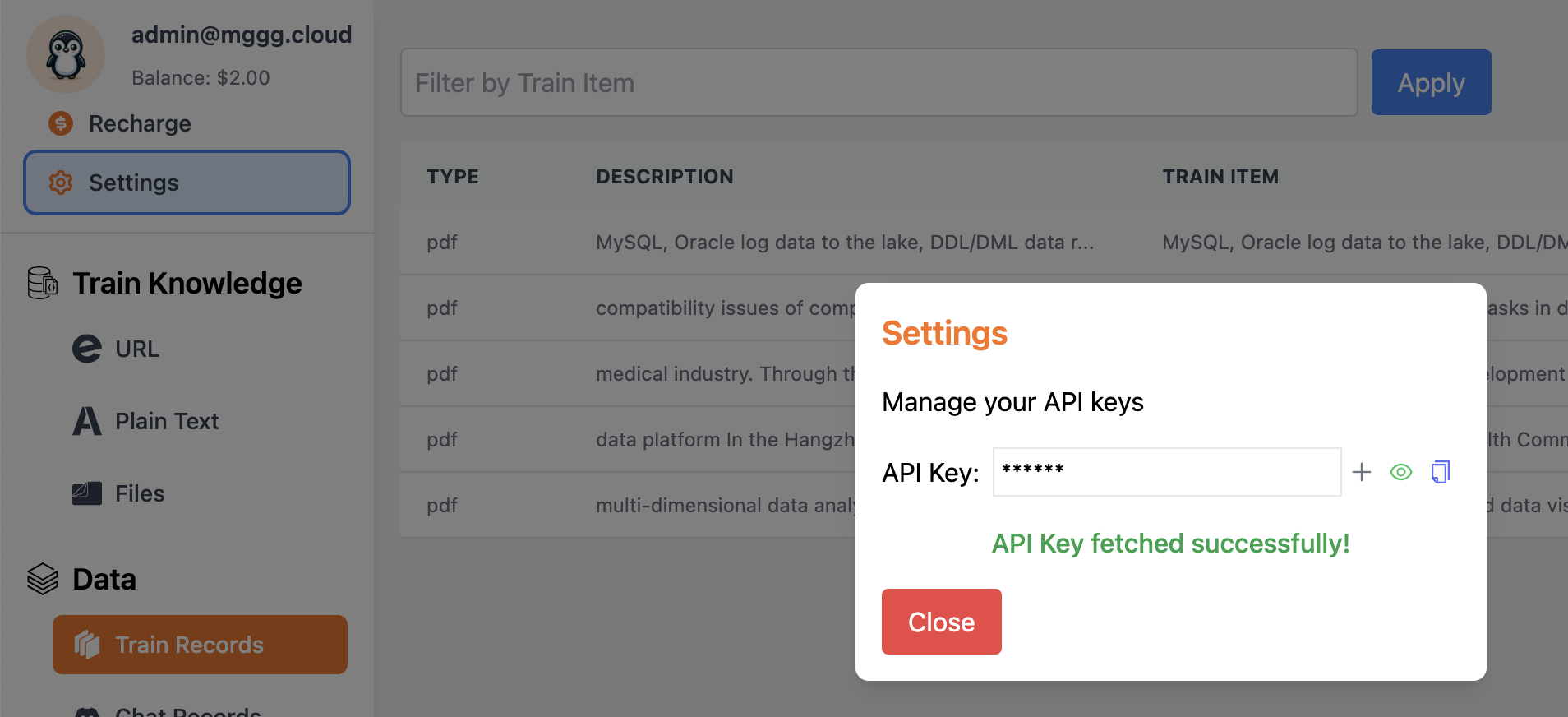
Example Query: Experience Related to Data Platforms
To query the knowledge base, use the following JSON request body, where "query": "Experience related to data platform." represents the information you’re seeking.
The request is made to https://api.gptdevelopment.online/api/embeddings/train/query using the POST method. Authentication is performed using a JWT token obtained from the Settings menu.
Here’s an example CURL command for testing (remember to replace ${token} with your actual API Key):
curl -X POST 'https://api.gptdevelopment.online/api/embeddings/train/query' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ${token}' \
-d '{"query": "Experience related to data platform."}'
The response from the query should provide detailed information based on the trained data. For instance:
Through the development of a self-researched data integration framework and various
data source extraction plugins, including Oracle,
MySQL, PostgreSQL, MongoDB, HTTP, custom protocols, etc.,
achieved rapid data extraction and integration,
significantly improving the efficiency and stability of the data platfor